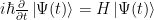If you are a heavy editor in WordPress, you may find out that most of the time, you just set the first image of your post to be the featured image. Here’s a quick and handy way to help you skip the tedious work and save some labor.
Once activated, this plugin will automatically set the post’s featured image to be the first image in your post content if your post doesn’t have a featured image yet.
If you want to select your own featured image, it will leave the featured image untouched and display your selection instead.
How this works
Let’s take a look at the plugin’s code, which is very simple.
if ( function_exists( 'add_theme_support' ) ) {
add_theme_support( 'post-thumbnails' ); // This should be in your theme. But we add this here because this way we can have featured images before swicth to a theme that supports them.
function easy_add_thumbnail($post) {
$already_has_thumb = has_post_thumbnail();
$post_type = get_post_type( $post->ID );
$exclude_types = array('');
$exclude_types = apply_filters( 'eat_exclude_types', $exclude_types );
// do nothing if the post has already a featured image set
if ( $already_has_thumb ) {
return;
}
// do the job if the post is not from an excluded type
if ( ! in_array( $post_type, $exclude_types ) ) {
// get first attached image
$attached_image = get_children( "order=ASC&post_parent=$post->ID&post_type=attachment&post_mime_type=image&numberposts=1" );
if ( $attached_image ) {
$attachment_values = array_values( $attached_image );
// add attachment ID
add_post_meta( $post->ID, '_thumbnail_id', $attachment_values[0]->ID, true );
}
}
}
// set featured image before post is displayed (for old posts)
add_action('the_post', 'easy_add_thumbnail');
// hooks added to set the thumbnail when publishing too
add_action('new_to_publish', 'easy_add_thumbnail');
add_action('draft_to_publish', 'easy_add_thumbnail');
add_action('pending_to_publish', 'easy_add_thumbnail');
add_action('future_to_publish', 'easy_add_thumbnail');
}
What this code does is that it creates a function called easy_add_thumbnail, which checks if a featured image has been set for your post, and then if a featured image hasn’t been set, it will scan through the images in your post and assign one of them to be the featured image.
Next, this code hooks that easy_add_thumbnail function to the post editing events so that the function will be called every time the post is published or displayed (for old posts).
If you don’t want to install the plugin, you can just add this code snippet to your theme’s function.php file or create your own plugin, whichever you prefer.
Does Easy Add Thumbnail plugin work well with Image Teleporter plugin?
If you don’t know it yet, Image Teleporter plugin helps you upload all the external hosted images in your post to your WordPress hosting and then change the images’ url correspondingly.
Fortunately, Easy Add Thumbnail works well with Image Teleporter. This means that even if the images in your post are hosted externally, when you update or publish your post, the Image Teleporter will first upload them to your hosting and attach the new internally hosted images to your post; then the Easy Add Thumbnail plugin will pick the first among those internal hosted images and set it as the featured image (if you haven’t specified a featured image by that time).
WordPress is no doubt the most popular framework for building a website. With WordPress, you can build a website from scratch within 5 minutes. If you are a WordPress beginner, the following plugins may help you get started even faster.
Insert headers and footers configuration screenshot
This plugin lets you insert JavaScript, meta tags, html tags, etc. in the header or footer of all pages in your website. While the concept is simple, this plugin becomes super handy when you want to add 3rd party services to your website via html or JavaScript.
Adding Google Analytics tracking script
If you don’t know it yet, Google Analytics is the best analytics tool out there for your website and what’s even better is it’s totally free. I believe almost every website in the world is integrated with Google Analytics. Therefore, I would highly recommend that you have your website integrated with this amazing tool.
When you want to integrate Google Analytics tracking script into your WordPress website, just copy the script provided by Google and paste it into the footer slot in the plugin configuration page. That’s it! Done! No additional plugin needed. No HTML editing needed. Your site is now fully integrated with Google Analytics.
Adding Webmasters Tools (Search Console) verification meta tag
While Webmasters Tools provide a lot of ways to verify your ownership of your website, the easiest way would be adding the verification meta tag to your website’s header. With Insert Headers and Footers plugin, it is as easy as copying and pasting the verification meta tag into the header slot in the plugin configuration page. Save the configuration and now you can go to Webmasters Tools and ask Google to verify your website.
Adding other 3rd party JavaScript
As your web building journey goes on, you will find yourself integrating a lot more 3rd party services to your website via JavaScript. In most of the cases, the 3rd party tells you to add a tracking script to the header or footer of every page in your website.
With this plugin installed, you just have to go to the plugin configuration page and add the new script to the existing other scripts that are already there. Oh! Did I forget to mention that you can add multiple scripts to the same slot (header or footer)? You can do that just by pasting the scripts one after another in the slot you want (header or footer). The whole slot’s content will be rendered into the html of every page in your website.
Header or footer?
In most of the cases, 3rd party scripts can be inserted into either header or footer and still work perfectly. However, whenever it’s possible, you should put the scripts in the footer because that will make your website load faster as your website will have a chance to render the content before loading the JavaScript.
This plugin makes your SEO life a lot easier, especially if you are a beginner to SEO.
After this plugin is installed and activated, it will give you a configuration page with several tabs. The configurations are very easy to understand and the default settings are good enough, so you can just leave the default there and you’re good to go.
Now your website front-end already has the following features:
Auto generated meta description, social sharing meta tag (based on configured template),
Auto generated meta title (based on configured template),
Auto generated sitemap xml (default to yoursite/sitemap_index.xml).
And your back-end is provided with the following tools:
A dashboard on SEO performance,
Titles and Metas configurations,
Social platform integrations,
XML sitemaps configurations,
Robots.txt editor.
Yoast SEO also adds a form in your regular post editor, where it allows you to specify a keyword that you want your post to focus on, and then it uses some best practices’ rules to score the SEO performance of your post versus that focused keyword and also score the readability of the post. It also tells you what you did well and what you can improve to make your score better.
Yoast SEO has more than 1 million active installs (as of 2016). The number says it all. I would definitely recommend this plugin, especially if you are new to SEO.
When you copy the image from another web page to your post editor, the image URL is still from the original host, not your WordPress website’s host. This plugin turns images in your posts that are hosted externally into images that are uploaded to your Media Library.
When you finish editing your post and hit Publish or Update, this plugin finds images that are still hosted externally in your post, downloads them, uploads them to your Media Library, changes the image links of your post to the Media Library version and saves the post again.
By changing the external linked image to your Media Library, your website performance will not be affected by the external host performance. Moreover, if the external host goes down, the images on your posts will still load beautifully.
Imagine the workload you would have to do without this plugin: downloading, uploading, inserting the image for every image in your post, multiplied by the number of posts you have; not to mention the troubles when the external host goes down several years later. Now, while this brilliant plugin is doing all the hard work, you can go out and drink beers with your buddies!
Jetpack provides us with a lot of cool features out of the box. Below are some of those:
Photon – free CDN hosting service by Jetpack. Jetpack automatically cache images on our website on their CDN and serve static contents like images on our website to our visitors from their CDN. This feature helps releasing stress to our server, with no cost at all.
Site stats: traffic, visitors
Infinite scroll: Load more posts as the reader scrolls down
Social: Add social sharing buttons to your posts, automatically share your posts to your fan page
There are a lot more waiting to be discover. I would recommend that you give this awesome plugin a try.
SiteOrigin Page Builder is the most popular page creation plugin for WordPress. It makes it easy to create responsive column based content, using the widgets you know and love. Your content will accurately adapt to all mobile devices, ensuring your site is mobile-ready. Read more on SiteOrigin.
With SiteOrigin, your editors immediately become professional html designers. All of the layouts, components like google maps, carousel slider, etc. that you can think of, can be done with SiteOrigin using only drag-and-drop. No single line of code or html editing will be necessary.
I would strongly recommend that you install this plugin and give it a try.
If your website content does not need to be 100% real-time, this plugin can help a lot with your hosting cost, because you can now use only one tenth of your hardware resources to serve the same amount of traffic. Moreover, the settings are pre-configured out of the box. You can install the plugin and just use the default options, yet everything still works perfectly.
This plugin generates static html files from your dynamic WordPress blog. After a html file is generated your webserver will serve that file instead of processing the comparatively heavier and more expensive WordPress PHP scripts.
The static html files will be served to the vast majority of your users, but because a user’s details are displayed in the comment form after they leave a comment those requests are handled by the legacy caching engine. Static files are served to:
Users who are not logged in.
Users who have not left a comment on your blog.
Or users who have not viewed a password protected post.
99% of your visitors will be served static html files. Those users who don’t see the static files will still benefit because they will see different cached files that aren’t quite as efficient but still better than uncached. This plugin will help your server cope with a front page appearance on digg.com or other social networking site.
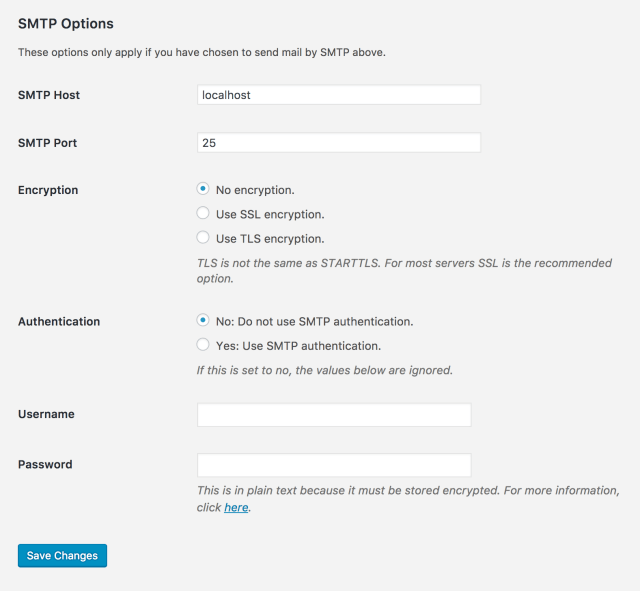
Some cloud hosting, including Google Cloud, Amazon Web Services and Microsoft Azure Cloud, won’t let us send emails via SMTP from within the web server. To send emails, we should use some 3rd party email services like SendGrid, MailGun, etc. that allow us to use some custom SMTP port, that can get through the cloud firewall policy.
This plugin helps us configure SMTP and also test the configuration easily with only one page of configuration. Without this plugin, configuring SMTP settings and testing them would be a pain, especially if you don’t have ssh access to the hosting server.
The plugin configuration page is so simple that an average user can do it by himself.
If you are looking for a contact form for your website, look no more. Contact Form 7 plugin provides a contact form out of the box. It also integrates well with Google’s ReCaptcha service to prevent your websites from spams. The configurations are simple yet very flexible.
If you already have SiteOrigin plugin installed, SiteOrigin also comes with a very powerful contact form in their Page Builder feature. In my opinion, SiteOrigin’s contact form and Contact Form 7 are equally good. It’s only a personal preference matter when it comes to choosing which to use.
Conclusion
In this topic, I have mentioned the plugins that I find useful and install on all of my WordPress websites. Hope they can help you, too!
What are your favorite WordPress plugins? Let me know in the comments! 😀
Nowadays, web applications are becoming more and more popular. Large websites are serving billions of users everyday, with minimal to zero percent down-time. Since you are reading this article, there’s a high chance you are already running a large system or are going to build one.
In this blog series, I’m going to share my experience on how to design web applications for scalability. This first article is not intended to go into too much detail, but instead to give you a rough idea of what should be considered when designing a scalable web application. I’m going to share the way I think when designing a scalable system, and not the solution to any specific system.
This ideas mentioned in this blog series not only apply to building websites, but also to building applications and software systems in general.
Scalability is the capability of a system, network, or process to handle a growing amount of work, or its potential to be enlarged to accommodate that growth.
Let’s look at an example. Our application may currently be running on a 2 CPUs with 8 GB memory instance, serving two million page views per day. What if that number of page views gets doubled by tomorrow, then ten times larger by next week, and then, a thousand times larger by the end of next month? Is our application prepared for that? What are the plans to handle the extra workloads? Are we going to upgrade our server to a larger one? Or are we going to buy more servers? Or is there anything else we are going to do?
If our application is prepared for the growth of users or page views or transactions, our application is scalable.
The plans that we prepare for our application to grow, or in other words, scale, with the growth of users or transactions, are called the scaling strategies.
Designing such a plan so that our application can scale, is designing for scalability.
Scalability, simply, is about doing what you do in a bigger way. Scaling a web application is all about allowing more people to use your application. If you can’t figure out how to improve performance while scaling out, it’s okay. And as long as you can scale to handle larger number of users it’s ok to have multiple single points of failures as well. — Royans K Tharakan
Vertical Scalability vs. Horizontal Scalability
We have two choices when it comes to scaling: Vertical and Horizontal.
Vertical Scalability – Vertical scaling means that scales by adding more power (CPU, RAM) in your existing machine. It basically means promoting an upgrade on the server. An example of this would be to add CPUs to an existing server, or expanding storage by adding hard drive on an existing RAID/SAN storage.
Horizontal Scalability – Horizontal scaling means that scales by adding more machines in your resource pool. It is the ability to increase the ability to connect multiple instances so that they function as a single logical unit. Basically, it means increasing the number of servers. Most clustering solutions, distributed file systems, load-balancers help you with horizontal scalability.
If you need scalability, urgently, going vertical is probably going to be the easiest (provided you have the bank balance to go with it). In most cases, without a line of code change, you might be able to drop in your application on a super-expensive 64 CPU server from Sun or HP and storage from EMC, Hitachi or Netapp and everything will be fine. For a while at least. Unfortunately Vertical scaling, gets more and more expensive as you grow.
Horizontal scalability, on the other hand doesn’t require you to buy more and more expensive servers. It’s meant to be scaled using commodity storage and server solutions. But Horizontal scalability isn’t cheap either. The application has to be built ground up to run on multiple servers as a single application. Two interesting problems which most application in a horizontally scalable world have to worry about are “Split brain” and “hardware failure“.
While infinite horizontal linear scalability is difficult to achieve, infinite vertical scalability is impossible. If you are building capacity for a pre-determined number of users, it might be wise to investigate vertical scalability. But if you are building a web application which could be used by millions, going vertical could be an expensive mistake.
But scalability is not just about CPU (processing power). For a successful scalable web application, all layers have to scale in equally. Which includes the storage layer (Clustered file systems, s3, etc.), the database layer (partitioning, federation), application layer (memcached, scaleout, terracota, tomcat clustering, etc.), the web layer, loadbalancer, firewall, etc. For example if you don’t have a way to implement multiple load balancers to handle your future web traffic load, it doesn’t really matter how much money and effort you put into horizontal scalability of the web layer. Your traffic will be limited to only what your load balancer can push.
Choosing the right kind of scalability depends on how much you want to scale and spend. In fact if someone says there is a “one size fits all” solution, don’t believe them. And if someone starts a “scalability” discussion in the next party you attend, please do ask them what they mean by scalability first.
What do we want to achieve in a scalable system?
Scalability (duh!)
A scalable system should be prepared for a lot more workloads in the future. We can upgrade the servers to larger ones, with more CPUs and memory. We can design the system so that it can be extended by adding more servers to the existing application cluster. There should always be a scaling strategy so that the system can adapt to the upcoming extra workloads.
Robustness
A scalable system should always be responsive and function correctly, even when the number of requests grows by a factor of thousands. After all, there’s no point adding more hardware resources if the system cannot function correctly.
High availability
The system is going to server millions or billions of users, all around the world. Lots of businesses may depend on our system. Our system, therefore, cannot afford a down-time. The system should always be available, even during system upgrades. When our application goes global, there’s no place for “night deploys”.
3. Methodologies
Although there are a lot of specific ways to scale a system, they can be generalized into some methodologies below.
Methodology #1: Splitting the system
If you can’t split it, you can’t scale it. — Randy Shoup
Splitting is one of the most common practices in designing a scalable system. The idea is that, since vertical scaling the whole system is limited by hardware capability, we need to split the system into components and scale each component separately.
For example, let’s say we are designing an e-commerce system. At first, we have our web application and our database on the same server. When the traffic grows, we plans to buy a larger server. If we put our system on the most powerful server at the moment, it can handle up to one million concurrent users. And that’s it. We cannot scale to another million users because there’s no more powerful server that we can buy.
The first thing we can do is to split the system so that the web application is put on one server and the database on another.
Then, we can clone the web application to put on multiple servers, all accessing the same database server.
Then, we can split the database into multiple databases, each containing several tables from the original database. The sub-databases can now be put on separate servers. In an e-commerce system, the database can be split in to product database, order database, fulfillment process database, user and authentication database, etc.
Of course, we cannot split things that easily if we didn’t design our system for that from the beginning. For example, if our application joins data from two tables, these two tables cannot be split into different servers. This little example can show us the importance of designing a system for scalability from the early days.
HDFS, MapReduce, Kafka, ElasticSearch, and many more applications are designed to be able to split and scale by adding more servers to the application cluster.
Facebook split their databases not only by tables, but also by rows. Data of users in each region are saved on different “region databases”, and are synced periodically to other “region databases”.
Lots of large systems nowadays are split into microservices, each of which takes care of one function in the system, so that the services can be scaled separately.
As you can see, designing ways that our system can be split plays an important role in making our system scalable.
Methodology #2: Detecting and Optimizing Bottlenecks
The limit of a system is the limit of its weakest link.
To make the system handle more workloads, we need to find the system’s weakest point and make that point handle more workloads.
Let’s think of an example. In our e-commerce system, we have 5 web servers and 1 database server, each hosted on a separate physical server instance. The web servers are running at about 5% of CPU on average, while the database server is always running at 95% of CPU. The bottleneck of the system in this case is the database server.
In the above example, there’s no point adding more web servers to the system. If the current setup can handle one million concurrent users at most, it is not likely that adding more web servers can help the system to handle more users. Instead, optimizing the database server may help.
As discussed in the previous part, to optimize bottleneck at the database server, we can buy a more powerful server and relocate the database into it. If that is not an option, we can try to split the tables on the database into serveral sub-databases on different server instances, but that would include some code modifying, and may not be an option either.
Taking a closer look at the resouce usage on the database server, we find out that most of the time, the CPUs are not doing the computation, but are instead waiting for the I/O requests to complete. We monitor the disk I/O, just to find out that the disk-write is always at 100 MB/s. Now we know that the real bottleneck is the disk I/O.
To optimize the disk I/O bottleneck, we can upgrade our HDDs into SSDs, or we can add more disks to the RAID system, or try to use a SAN. As long as we can provide a better I/O bandwidth, the whole system may benefit.
On the other hand, we can reduce the I/O request by optimizing database queries and indexes. If after creating some database indexes, the disk I/O rate reduces to 10 MB/s, we may not need to upgrade the database server anymore. There were also many times in my past projects, the reason was that the database doesn’t have enough memory to cache the queries, and strange it may sound, but adding more memory could solve the disk I/O problems.
After optimizing the database, our system can handle another million users, but looking at the resources usage, we now see that the web servers are using 99% of CPU all the time, while the database only uses less than 10% of CPU. This time, the web servers become the bottleneck. We can repeat the optimizing process with the web servers. We can add more server instances, or detect and optimize the bad code block that is causing the rise in CPU usage. The point is that if the weakest link in the system can handle more requests, the whole system can handle more.
Methodology #3: Detecting and Eliminating Single Point of Failure (SPOF)
Since we mentioned bottlenecks in the previous part, I thought it’s worth discussing Single Point of Failure too. This part is more on keeping our system high available than enabling it to handle more requests. In fact, most large systems serve a lot of people and lots of businesses may depend on them, so high availability is one of the most wanted requirements.
A single point of failure (SPOF) is a part of a system that, if it fails, will stop the entire system from working. SPOFs are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.
In a traditional web application, we often have a web server reading and writing to a database. When a user open a browser and navigate to the website:
the browser sends a request to the web server,
the web server receives the request and gets data from the database or writes to it,
the web server responses to the browser with the result,
the browser renders the response to the screen.
In the above setup, if the web server breaks down (maybe due to hardware issues), the website is down. The user cannot connect to the website anymore. This web server is a Single Point of Failure, which means if it fails, the whole system fails.
The database server in this case is also a Single Point of Failure.
To make our system high available, which means the system can still function if some part of it goes down, we have to eliminate its Single Point of Failure.
The word “eliminate” doesn’t mean taking that part down, but instead, means trying to make that part no long the Single Point of Failure.
Back to our example, to eliminate the Single Point of Failure at the database, we can user the mirroring function of the database. We setup the database on 2 separate server instances, one as the master server and the other as the mirror server. If the master goes down, the mirror server will stand up to replace the master to make sure the web servers can still accessing the database.
For the web server, we setup another web server that function exactly the same as the first one. We setup a reverse proxy to load balance requests between the two web server. If a web server breaks down, the reverse proxy will detect and route all traffic to the remaining one.
We have eliminated two single point of failure in the system. However, we are introducing a new one: the reverse proxy.
In the new setup, the browser connects to the reverse proxy, the reverse proxy will then forwarding the request to the internal web server, wait for the response, then forward it back to the browser. If the reverse proxy goes down, the user still cannot access the website.
To eliminate this new single point of failure, we can setup a backup server for the reverse proxy and use a Virtual IP Address. The two reverse proxy server will continously check if the other is alive, and make sure that one of them is taking the Virtual IP Address. When the master reverse proxy goes down, the backup server will take the Virtual IP Address and take the job from the master.
Detecting and eliminating Single Point of Failure is no easy task in systems design. The example above is just a simple one to demonstrate the idea. We’ll have a whole blog on this later.
Methodology #4: Caching
I believe you’ve heard about caching and use it a lot in your projects. Let’s again look it up on Wikipedia:
In computing, a cache /ˈkæʃ/ kash, is a hardware or software component that stores data so future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation, or the duplicate of data stored elsewhere.
A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests can be served from the cache, the faster the system performs.
If your system has a lot of data that doesn’t changes for short period of time, or if the change isn’t critical and it doesn’t hurt to serve the user with an old version of the data, caching is a good candidate that can optimize your system by ten or even a hundred times.
For example, a news website doesn’t need to change its news every second. People can read a 5-minute-ago version of the news without any critical problems.
There are many types of caching, all serve the same purpose: to make future requests for that data can be served faster. A caching solution can be a mix among the following caching strategies:
Caching in disk
After being computed for the first time, a web page’s content may be cached into a file in the server’s storage. Next time the web page is requested, the server does not have to recompute the content, but read it directly from the cached file and response to the user. Most modern web servers (Apache, Nginx, IIS) and web frameworks (Django, PHP, .NET MVC) support this type of caching.
Caching in memory
After the data is read from the disk or computed from the database, it is cached in memory so that the data can be read a lot faster in the next requests. This type of caching is often used to cache data objects, and also used by image or video hosting servers.
Caching objects
Instead of caching the whole web page content, the system can cache objects that were read from the database into memory, so that next time, it doesn’t have to query it again from the database. This type of caching is often used in large systems that data are read a lot more often than written.
Caching in database
Computations can also be cached in a database. If the application does a lot of aggregations on raw data, and the aggregations does not need to be 100% updated everytime it is requested, we can ease the stress for the database by precomputing the aggregations and cache it in a separate database table, instead of scanning the whole raw data table to do the aggregations everytime receiving a request.
Distributed caching
If we need to share cached data among web servers, we may need to apply a distributed caching service of some kind to store the cached data. For example if we cache users’ session data on web servers’ memory, and use a load balancer to round robin requests among these web servers, we may face the situation where a user login with web server 1, the session cookie is stored on web server 1’s memory. Later when that user refreshes the page, she gets routed to web server 2, which has no session data of her. The result is that the user appears to be logged out, although she just logged in 5 seconds ago. To overcome this type of situation, we need a distributed caching solution. It can be a network shared folder to keep the session file, or it can be a distributed memory caching solution like memcached or Redis.
Caching can be powerful but should be used with care. Improper use of caching may cause serious problems. Here are some examples:
Caching account balance in a credit system is not the smartest thing to do, because it can lead to the situation where the accounts are overcharged.
Another common mistake is caching web page responses on a reverse proxy, including the response header information. It may happen like this:
For example, Alice goes to myshop.com, logs in, then browses the detail page of product A.
Web server renders the web content for product A, and caches it as a html file on the server’s disk storage, including the response header that set Alice’s authentication cookie
Meanwhile, Bob also wants to browse product A.
Web server serves Bob with the web content from the cached file, including Alice’s authentication cookie in response header
Bob is now seeing product A, and unintentionally logged in as Alice.
Bob can now see Alice’s order history. If Bob buys something on the website, the system may record that Alice buys it. Later, customer service agent calls Alice to confirm the order but Alice doesn’t understand what happened
The second example may sound stupid, but it did happen in one of my past projects. The reverse proxy application at that time somehow cached some urls that it was not configured to cache, leading to the situation described above. Turning off the proxy’s “kernel caching mode”, without modifying any url configuration, made the problem disappear.
There’s a lot more about caching, but that would be out of the scope of this blog. We’ll have another blog on this topic.
Methodology #5: Indexing
Indexing is a way of storing data in a suitable structure, so that data retrieval can be fast and accurate.
Database index
Sometimes, caching is not applicable due to the nature of the business, like in a banking system, where transactional data must always be consistent.
Database queries can be optimized by adding database index to the table. Database index can improve query performance by a factor of thousands to millions times. In fact, the query running time can get from O(n) in a full table scan, down to O(logn) in a indexed table, where n is the number of records in the table. Let’s say we have a table of 10.000.000.000 (ten billion) records, and the table is well-indexed, the query will need to do only 10 compares to find the matching row. Behind the scene, the indexed data is stored in a b-tree data structure, but that’s out of the scope of this blog.
Database indexing not only speed up the query running time, but also reduces the disk I/O needed to return the matching records. In OLTP databases, faster queries lead to less locking time on the table.
I’ve seen many times in my past projects, where the insert/update to the database took too long to complete, but the real reason was not the insert/update itself. The real cause was another select query, which took too long to complete and locked the whole table during its execution, making the insert/update queue up in line. Adding a index to optimize the select query, the problem is gone. The insert/update can complete and return immediately as usual.
If you want to learn more about database index, try reading use-the-index-luke.
Search index
When it comes to searching, there’s another hero in town: search index.
Most databases support full-text index out of the box, but it’s hard to configure and does not scale very well. Search queries can be very complicated, like searching for a product with a keyword that should appear in its title or content, and the product must be in sports and clothes category, with a discount percent at least 50 percent. The database can be used to fulfill the search, but the performance would be terrible.
At the moment, Solr and ElasticSearch are the most popular search engines that are being used widely. They are fast, horizontally scalable, good at full-text search and handling complicated queries.
Using a search engine in our system can yield several benefits:
Search engines will take care of what it is best at: searching, while leaving the database to do what the database is best at: storing transactional data.
Most search engines are design to scale very well horizontally. Therefore, by using a search engine, our system’s search function are already prepared for scaling. For example, ElasticSearch can be deployed in cluster of multiple nodes. When we need extra performance from the cluster, we can add more nodes to the cluster, or we can just increase the number of replicas of the index, all of which can be done online without shutting down the service.
Increasing number of replicas will enable more nodes to store the same piece of data, and hence ElasticSearch can load balance the query to get the result from more nodes, which leads to the increase in query performance.
Think of what would happen if we do the search directly from the database. The scaling would be a disaster.
With all the benefits mentioned above, using a search engine will give you some extra work to do, like to index or synchronize the data from the database to the search engine. But if your system is going to scale, the benefits are going to worth the extra effort.
Methodology #6: Classifying and Prioritizing Data
Not all data are created equal.
When our system grows too large and too complicated, we may not be able to work out a way to scale all our data together. Facebook has more than a billion users, each user has hundreds to thousand of friends, each friend has several status updates and activities every day. If everytime a user create a status, we have to notify all of the friends about that new activity in one database transaction, no system would be above to handle the workload, and even if it can, the user would have to wait very long before his or her status post completes, just because he or she has more than a thousand friends to update along the way.
Real-time vs. Near real-time vs. Offline
During a Facebook developer event, talking about how Facebook partitioned the users to multiple databases, each database containing a subset of users, and synchronize the “activity feeds” among databases, the speaker was asked: “How did Facebook keep the data consitent among databases?”. At that time, the answer blew my mind: “Fortunately, we don’t have to be consistent at all”.
In Facebook’s case, of course it’s good to notify the friends about a user’s new status right away, but it at the same time doesn’t hurt if the notification is 5 minutes later or even an hour later, not to mention half of those friends may not even be online by that time.
In an e-commerce system, most of the reports aren’t necessary to be real-time. Some of the reports can even be updated weekly or monthly (yes, I’m talking about those weekly and monthly sales performance reports :D)
Before designing a solution to scale the system, we should first classify each data into one of these types: real-time, near real-time, and offline.
Real-time: These data need to always be consistent. In other words, everytime the data of this type is read, it must be the latest and the only version of the data. Data like bank account balance, warehouse stock quantity, GPS location in navigating system, chat messages should be in this category.
Near real-time: These data can afford to be a little bit late, for example five minutes or even one hour. For example, in most of the case, emails can be a little bit late without hurting anyone. Activity feed in the above section, can also be classified as near real-time. Of course, it’s always better if these data can be real-time, but if the cost to be real-time is too high, these data can fall back to be near real-time with mininal to zero negative impact. In fact, most people don’t care or even notice a delay in the activity notification.
Offline: These data do not need to be updated regularly. They can be updated in batches at the end of the day or at the end of a week, when the system is not heavily used. For example, in an e-commerce system, reconciliation reports can be exported once a day at night, when the traffic to the website is not that critical and the system resources are free.
Know the priority of our data, we can decide how each data should be stored and should be scaled. Real-time data should be stored in a transactional database, while near real-time data can put in a queue waiting to be processed with a small delay. Offline data can be put in a replicated database, which is synchronized once a day during low traffic hours. The system then can use significantly less resources while still be able to fulfill the business requirements.
Read-heavy vs. Write-heavy
Beside the above mentioned classification, we should also take into consideration whether our data is read-heavy or write-heavy
Read-heavy: These data are read a lot more frequently than written or updated. For example, articles in a newspaper or a blog are rarely updated, but are read very frequently. For these type of data, we can use caching or replication to enable the system to read more in less time.
Write-heavy: These data are written a lot more frequently than read. For example, access logs in a system or bank transactions. For these type of data, caching or replication may not be helpful. In fact, caching or replication may even hurt the system performance, since the system have to do more works every time it has to write something, while it can rarely read a data from cache. The data may have been changed a hundred times before it is read from cache one time.
Other classifications
Above are just two ways of classify and prioritize data before desiging an appropriate scaling stategy for each type of data. In practice, we can think of more ways to classify the data. The point is, we should classify the data based on business needs and select an appropriate strategy so that the system can use less resources and can still meet the business requirements.
4. Where to go from here?
The above topics are just some of the most basic topics on designing a scalable system. There’s a lot of things that I haven’t learned or haven’t even known of. I’m going to list some topics that can be helpful when designing a scaling strategy. Hope some of them can be helpful to you. The more we know, the higher the chance we can find a good scaling solution for our system. The below topics are not listed in any intended order.
CAP theorem
How to become horizontally scalable in every layer
Vertical partitioning vs. horizontal partitioning
Read-heavy vs. write heavy
Clustering: partitioning vs. replication
Real-time vs. near real-time vs offline
How to make web server horizontally scalable using reverse proxy
How to make reverse proxy horizontally scalable
How to make database horizontally scalable
Shared nothing database cluster vs. shared storage database cluster
MySQL NDB vs. Percona vs. Oracle Database Cluster vs. SQL Server Cluster
Using cloud database service vs. scaling self-hosted database
Scaling system on cloud hosted environment vs. self hosted environment
DNS round robin
Caching
Disk caching
Local memory caching
Distributed memory caching
memcached
Redis
Hardware scaling
RAID storage
SAN storage
Fiber network interface
Network capacity consideration
Local cache vs. network distributed cache
local pre-compute to reduce network traffic (e.g. MapReduce Combiner)
Scaling storage capacity (RAID, distributed network storage, data compression, etc.)
Database/datawarehouse optimization
Database index
Column store index vs. row store index
Search optimization (ElasticSearch, Solr)
Peak-time preparation strategies (cloud vs. self-hosting, AWS Auto Scaling, Google Cloud Autoscaler
Cost optimization
Google Cloud Preemptible, AWS Spot Instance
Free CDN: CloudFlare, Incapsula
Resources monitoring, debugging, troubleshooting
Automate everything
Load test vs. stress test
Conclusion
When it comes to scaling, there’s no magical solution that can tackle all problems on all systems. Knowing the basics and the methodologies, we can do the analysis and find the most suitable solution, and prioritize what can be done first that will results in the biggest impact.
On the other hand, there’s no final destination in optimizing system’s scalability. Whenever we sense that our system is reaching its limit, we should work out a better solution to scale it up before it’s too late. However, if there’s no sign that the system will get overloaded anytime soon, I believe you’ll always have better works to do than further optmizing the system. If there’s only 10 billion people on earth, there’s no point designing a system for 100 billion concurrent users.
This article can no way cover everything in designing scalable systems. But I hope some of it might be helpful to you. What’s the most interesting experience you’ve got when scaling your system? Share with us in the comment! 😀
Sorry for the long post!
How to type math notations using LaTex syntax in your WordPress
If you have Jetpack by WordPress.com plugin installed and activated in your WordPress, the good news is Jetpack comes with a LaTex rendering function out of the box.
To use this function, first ensure that you have enabled it in Jetpack’s settings.
Now you can go to your blog post and insert the following code:
If you are using WordPress and want to include the above script, you can use Insert Headers and Footers plugin and paste the script in the plugin’s setting.
After the script is included, all the LaTex you type will turn into beautiful math notations effortlessly.
Examples
Example #1
When \(a \ne 0\), there are two solutions to \(ax^2 + bx + c = 0\) and they are
$$x = {-b \pm \sqrt{b^2-4ac} \over 2a}.$$
will output:
When \(a \ne 0\), there are two solutions to \(ax^2 + bx + c = 0\) and they are
$$x = {-b \pm \sqrt{b^2-4ac} \over 2a}.$$
Notice that using \( ... \) results in inline LaTex block, while using $$ ... $$ results in LaTex block in a separate line.
By this time, you may have already wondered, what if you want to show the plain original LaTex code instead of the converted math notations, like the LaTex codes pasted in the above examples?
The answer is simpler than expected: just put the LaTex code nested inside a <pre> </pre> tag. MathJax is smart enough to skip anything that is nested inside <pre> </pre>.
Now, if you want that original LaTex codes beautifully highlighted, you may want to check Google’s code-prettify library. But that’s another story :D.